

Maximizing the Impact of Your PhD Manuscript: Challenges and Publishing Opportunities
January 7, 2024
Recent PhD Topics in Artificial Intelligence 2023
January 7, 2024A Classification Methods of Big Data Analysis to Predict Diabetes Diseases
The healthcare industry faces increasing complexity as it processes large amounts of health records. Big data analysis techniques are becoming unstructured, necessitating the development of data analytics to predict diabetes, a leading cause of death worldwide. This Blog focuses on supervised classification techniques and their accuracy, aiming to identify the most effective algorithm for predicting diabetes development.
Introduction
Diabetes is a prevalent non-communicable disease (NCD) affecting millions worldwide. Researchers, hospitals, and doctors are utilizing healthcare data to understand clinical context, prevent future health issues, and discover new treatment options. Factors like age, insulin, blood pressure, and skin thickness can affect diabetes. The vast amount of information available about diabetes can enhance the social insurance system and improve treatment facilities.
✔ Check out our sample PhD Big Data Analysis to see how big data analytics examples are structured.
Big Data Analytics and Its Characteristics
Big data analysis is a word used to describe massive volumes of data. This big data establishes both organized and unstructured data that is developing swiftly and gradually. Because traditional database systems are incapable of handling extensive large data volumes, it is difficult to organize and examine this data in order to reach useful conclusions. Big Data processing and analysis may help a wide range of sectors, including Biological life science, engineering, finance, business, social work, and healthcare.
Characteristics:
Data technology is built on the five main qualities of big data, which include volume, velocity, variety, truthfulness, and value.
- Volume: The volume of data produced by a company or organization.
- Velocity: This is the rate at which data is produced and distributed.
- Variety: It refers to the data’s many data forms.
- Veracity: It represents the degree of uncertainty in the data.
- Value: The value emphasizes the data that is created as a result of certain business activities.
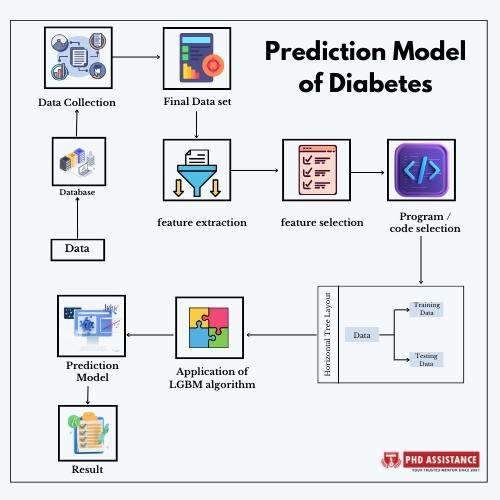
Classification methods in big data analysis
Several classification techniques in data mining can be used to predict diabetes based on historical data and relevant features. These methods can help identify patterns and make predictions about whether an individual is likely to have diabetes data analysis in Python or not. Here are some commonly used classification methods for predicting diabetes:
- Random Forest
- Random Forest is an ensemble learning method that uses multiple decision trees to make predictions.
- It can handle a large number of features and is less prone to overfitting.
- It provides feature importance scores.
- Support Vector Machines (SVM)
- SVM is a powerful classification method that works well for both linear and nonlinear data.
- It finds the optimal hyperplane that best separates the data into different classes.
- Kernel SVM can handle nonlinear relationships between features and outcomes.
- k-Nearest Neighbors (k-NN)
- k-NN classifies data points based on the majority class among their k-nearest neighbours.
- It’s a simple and intuitive method but can be sensitive to the choice of the number of neighbours (k).
- Naive Bayes
- Naive Bayes is based on Bayes’ theorem and is often used for text classification but can also be applied to health-related datasets.
- It assumes independence between features (naive assumption), which may not always hold in real-world data.
Proposed framework of diabetes prediction
When using any of these methods for diabetes data science prediction, it’s important to follow a standard big data analysis workflow, which includes data preprocessing, feature selection or engineering, model training and evaluation, and validation on independent datasets to ensure the model’s generalization ability. Additionally, consulting with domain experts and considering ethical and privacy concerns when dealing with medical data is crucial.
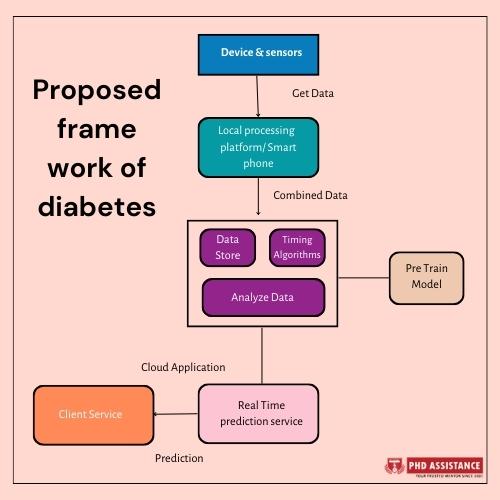
Big Data Analysis in predictive analytics in health care
-
- Data, which can manage a large quantity of data obtained from the healthcare sectors and ensures answers to key problems that develop in the medical business, plays an important role in predictive analytics, especially in the medical domain.
- Big Data analysis in the medical profession is developing as a potential technology that may be used to increase prediction, performance, innovations, and comparative effectiveness by collecting enormous volumes of healthcare data from patients and the public. The existing information sources may become knowledgeable sources that fuel the healthcare system by merging data and next-generation analytics into clinical research.
Check out our study guide to learn more about conducting statistical data analysis.
Conclusion
To conclude, predicting diabetes using machine learning and classification methods in data analysis is a crucial application in healthcare. The choice of method should depend on the dataset characteristics and specific objectives. Nonetheless, all these methods require rigorous big data preprocessing, feature engineering, and thorough model evaluation. It’s imperative to collaborate with medical experts and prioritize patient data privacy. Ultimately, the successful implementation of these methods can aid in early diagnosis and intervention, improving the management of diabetes and enhancing overall public health. Big data analysis aids in providing patients with affordable treatment and care. By performing proactive diagnosis in order to construct the nation in economic mode with less risk, we can avoid the effects of diabetes in the future.
About PhD Assistance
At PhD assistance, we assist big data analytics across a wide range of disciplines, demonstrating all expertise, intellectual ideas, critical analysis and evidence of original thoughts. We give you the opportunity to brainstorm with our big data analysts, who will explain how to use technologies such as Map Reduce, Apache Hadoop, Apache Spark, Apache Hive, NoSQL Database, Spark SQL, MongoDB, and Deep Learning for classification trees, regression, sentiment analysis, network analysis, and association rule learning and implement in your research with latest research topics.
References
-
- S. Hovan George, Aakifa Shahul, A. Shaji George, T. Baskar, & A. Shahul Hameed. (2023). A Survey Study on Big Data Analytics to Predict Diabetes Diseases Using Supervised Classification Methods. Partners Universal International Innovation Journal, 1(1), 1–8.
- Bachechi, Chiara, Laura Po, and Federica Rollo. “Big data analytics and visualization in traffic monitoring.” Big Data Research27 (2022): 100292.
- Wang, Lidong, and Cheryl Ann “Big data analytics as applied to diabetes management.” European Journal of Clinical and Biomedical Sciences 2.5 (2016): 29-38