

What data needs to be collected for a PhD in Machine Learning?
May 14, 2021
COMPUTER SCIENCE DISSERTATION TOPIC IDEAS FOR PHD SCHOLAR
May 22, 2021Machine Learning On Big Data: Opportunities And Challenges- Future Research Direction For Phd Scholars
In-Brief:
Machine Learning (ML) is rapidly used in a variety of applications. It has risen to prominence in recent years, owing in part to the emergence of big data. When it comes to big data, ML algorithms have never been more promising. Big data allows machine learning algorithms to discover finer-grained patterns and make more timely and precise predictions than ever before; however, it also poses significant challenges to machine learning, such as model scalability and distributed computing.
INTRODUCTION
In various fields as computer vision, speech recognition, natural language comprehension, neuroscience, fitness, and the Internet of Things, ML techniques have had enormous societal impacts. The emergence of the era of big data has stirred up interest in Machine Learning Big Data has never promised or questioned machine learning algorithms to gain new insights into a variety of business applications and human behaviours. On the one hand, big data provides ML algorithms with unparalleled amounts of data from which to derive underlying patterns and create predictive models; on the other hand, conventional ML algorithms face crucial challenges such as scalability in order to fully unlock the value of big data. With the ever-expanding world of big data, ML must develop and grow in order to turn big data into actionable intelligence.

ML aims to answer the question of how to build a computer system that improves itself over time [1]. The problem of learning from experience with respect to certain tasks and performance metrics is referred to as an ML problem. Users may use ML techniques to deduce underlying structure and make predictions from large datasets. ML thrives on strong computational environments, efficient learning techniques (algorithms), and rich and/or large data. As a result, ML has a lot of potential and is an essential part of big data analytics [2].
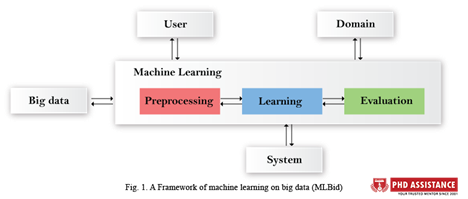
MACHINE LEARNING
Data pre-processing, learning, and assessment are common stages of Machine Learning. Data pre-processing aids in the transformation of raw data into the “right form” for further learning steps. Via data cleaning, extraction, transformation, and fusion, the pre-processing phase transforms such data into a form that can be used as inputs to learning. Using the pre-processed input data, the learning step selects learning algorithms and tunes model parameters to produce desired outputs. Data pre-processing can be done with some learning methods, especially representational learning. After that, the trained models are evaluated to see how well they do. The essence of learning input, the goal of learning activities, and the timing of data availability are all characteristics of machine learning.
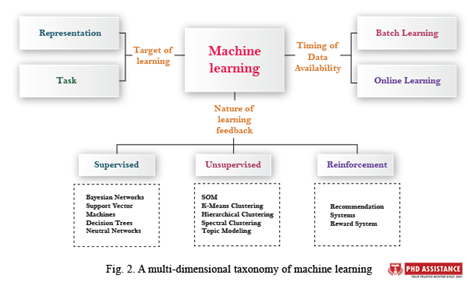
ML can be divided into three major categories based on the quality of the input available to a learning system: supervised learning, unsupervised learning, and reinforcement learning [5]. ML can be divided into two types: representational learning and task learning, depending on whether the learning goal is to learn particular tasks using input features or to learn the features themselves. Each Machine Learning Algorithm can be classified in a variety of ways.
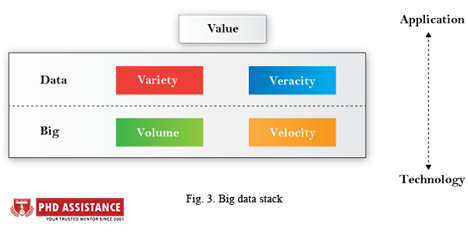
BIG DATA
Volume, velocity, variety, veracity, and value are the five dimensions of big data. Starting from the bottom, we organised the five dimensions into a stack of high, data, and value layers. The data layer is integral to big data, and the meaning factor characterises the influence of big data real-world applications. The lower layer is more reliant on technical advancements, while the higher layer is more focused on applications that leverage big data’s strategic strength. Established machine learning paradigms and algorithms must be modified to understand the potential of big data analytics and to process big data efficiently [4].
We recognise key opportunities and challenges in this section. We go through them individually for each of the three phases of machine learning: preprocessing, learning, and assessment.
DATA PREPROCESSING OPPORTUNITIES AND CHALLENGES
Data redundancy
When two or more data samples represent the same object, duplication occurs. Data replication or inconsistency can have a significant impact on machine learning. Traditional methods such as pairwise similarity comparison are no longer feasible for big data, despite a variety of techniques for detecting duplicates produced in the last 20 years [11]. Furthermore, the conventional presumption that duplicated pairs are rarer than non-duplicated pairs is no longer true. Dynamic Time Warping can be much faster than current Euclidean distance algorithms in this regard [11].

Data heterogeneity
Big data promises to include multi-view data from a variety of repositories, in a variety of formats, and from a variety of population samples, and thus is highly heterogeneous. The value of these multi-view heterogeneous data. As a result, combining all of the characteristics and treating them equally relevant is unlikely to result in optimal learning outcomes. Big data offers the possibility of simultaneously learning from different views and then assembling multiple findings by learning the relevance of feature views to the task. The approach is supposed to be resistant to data outliers and to be able to solve optimization and convergence problems.
Data discretization
However, most current discretization methods would be ineffective when dealing with large amounts of data. Traditional discretization approaches have been parallelized in big data platforms to solve big data problems, with a distributed variant of the entropy minimization discretizer based on the Minimum Description Length Principle improving both efficiency and accuracy.
Data labelling
Active learning can be used as an optimization technique for marking activities in crowd-sourced databases, reducing the number of questions posed to the crowd and enabling crowd-sourced applications to scale. Designing active Learning Algorithms for a crowd-sourced dataset, on the other hand, presents a number of practical challenges, including generality, scalability, and usability [12]. Another problem is that such a dataset cannot cover all user-specific contexts, resulting in output that is often inferior to user-centric training [13].
Imbalanced data
Traditional stratified random sampling approaches have tackled the problem of unbalanced data. However, if iterations of sub-sample generation and error metrics measurement are needed, the process can take a long time. Furthermore, conventional sampling methods are unable to support data sampling over a user-specified subset of data that includes value-based sampling efficiently. Parallel data sampling is needed by big data.
EVALUATION OPPORTUNITIES AND CHALLENGES
| Main Component | Aspects | Open research issues | References |
| Big Data | Volume | · Cleaning and compressing big data
· Large scale distributed feature selection · Workflow management and task scheduling |
[7] |
| Velocity | · Multi-view learning for heterogeneous multimedia data
· Multimedia neural semantic embedding |
||
| Variety | · Multi-view learning for heterogeneous multimedia data
· Multimedia neural semantic embedding |
[8] | |
| Veracity | · Assessing data veracity
· Learning with unreliable or contradicting data |
||
| Value | · Explainable ML for decision support
· Multi-user collaborative decision support based on big data analysis |
||
| User | Labeling | Crowd sourced active learning for effective large scale data annotation | [3] |
| Evaluation | Comprehensive evaluation measures for ML (e.g, usability-based measures) | ||
| Privacy | Privacy preserving distributed ML | ||
| User Interface | · Visualizing big data
· Intelligent user interfaces for interactive ML · Declarative ML |
||
| Domain | Domain knowledge | Incorporating general domain knowledge (e.g., ontology, first-order logic, business rules) in ML | [9] |
| System | Infrastructure | · New infrastructure that seamlessly provides decision support based on real time analysis of large amount of heterogeneous and unreliable data.
· General big data middleware |
[6] |
FUTURE RESEARCH
This paper provides a summary of the benefits and drawbacks of machine learning on big data. Big data poses new possibilities for inspiring revolutionary and novel ML technologies to solve many associated technological problems and generate real-world impacts, while also posing multiple challenges for conventional ML in terms of scalability, adaptability, and usability. These opportunities and challenges can be used to evaluate current research in this field. According to the components of the MLBiD system, we also highlight some open Research issues in ML on big data, as shown in Table.
CONCLUSION
In conclusion, machine learning is needed to address the challenges faced by big data and to discover hidden patterns, information, and insights from big data in order to transform its potential into real value for business decision-making and scientific exploration. The combination of machine learning and big data points to a bright future in a modern frontier.
REFERENCES
- Janiesch, C., Zschech, P., & Heinrich, K. (2021). Machine learning and deep learning. Electronic Markets, 1-11.
- Tsai, C. W., Lai, C. F., Chao, H. C., & Vasilakos, A. V. Big data analytics: a survey. Journal of Big data, 2(1), 1-32.
- Tang, M., & Liao, H. (2021). From conventional group decision making to large-scale group decision making: what are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega, 100, 102141.
- Garoufallou, E., & Gaitanou, P. (2021). Big Data: Opportunities and Challenges in Libraries, a Systematic Literature Review. College & Research Libraries, 82(3), 410.
- Kato, N., Mao, B., Tang, F., Kawamoto, Y., & Liu, J. (2020). Ten challenges in advancing machine learning technologies toward 6G. IEEE Wireless Communications, 27(3), 96-103.
- Li, W., Chai, Y., Khan, F., Jan, S. R. U., Verma, S., Menon, V. G., & Li, X. (2021). A comprehensive survey on machine learning-based big data analytics for IoT-enabled smart healthcare system. Mobile Networks and Applications, 1-19.
- von Ziegler, L., Sturman, O., & Bohacek, J. (2021). Big behavior: challenges and opportunities in a new era of deep behavior profiling. Neuropsychopharmacology, 46(1), 33-44.
- Ferretti, A., Ienca, M., Sheehan, M., Blasimme, A., Dove, E. S., Farsides, B., … & Vayena, E. (2021). Ethics review of big data research: What should stay and what should be reformed?. BMC Medical Ethics, 22(1), 1-13.
- Confalonieri, R., Weyde, T., Besold, T. R., & del Prado Martín, F. M. (2021). Using ontologies to enhance human understandability of global post-hoc explanations of black-box models. Artificial Intelligence, 296, 103471.
- Sarker, I. H., Kayes, A. S. M., Badsha, S., Alqahtani, H., Watters, P., & Ng, A. (2020). Cybersecurity data science: an overview from machine learning perspective. Journal of Big Data, 7(1), 1-29.
- Niknam, S., Dhillon, H. S., & Reed, J. H. (2020). Federated learning for wireless communications: Motivation, opportunities, and challenges. IEEE Communications Magazine, 58(6), 46-51.
- Nguyen-Dinh, Long-Van, et al. “Combining crowd-generated media and personal data: semi-supervised learning for context recognition.” Proceedings of the 1st ACM international workshop on Personal data meets distributed multimedia.
- Mozafari, Barzan, et al. “Scaling up crowd-sourcing to very large datasets: a case for active learning.” Proceedings of the VLDB Endowment 8.2: 125-136.